Macのエンター2回の変換が鬱陶しいと思っている方へ
この記事は以下に移動しました。
どの席に座るかで他人の心理はわかってしまう。

こんにちは、あつかんです。
今日は心理系の記事を書いていこうと思います。
皆さんは、席に座るときに、どんなことを考えて席を選んでいますか?
ほとんどの人は、そこまで意識せずに席についていると思います。
しかし、意識していなくても席の選び方ひとつで、深層心理が現れます。
人間は無意識に、相手に抱いている心理条件によって、席に座る位置が変わってくるのです。
自分の位置に対して相手がどこに座るかを知っておくことで、相手は私に対してどのように思っているのかなどを予測できます。
今回は4つ座るパターンを紹介し、それに対する心理を見ていきたいと思います。
パターン① 角

①の席に座った人は、あなたに対してリラックスしています。気軽に話すことができ雑談に向いた位置です。相手があなたに対して親近感を持っていることが分かります。
パターン② 隣

②の位置は、あなたと共同作業をするようなときに適した座り方です。
この位置は体の接触が比較的に起こりやすいので、接触が起こっても不快に感じないような人が座ると予想されるため、②の人は親しい間柄だといえます。
恋人などは隣に座りますね。
パターン③ 真正面

この座り方は一般的な座り方です。
一方、対立や説得、競争などの深刻な話題の時にも真正面の席を選ぶことが多いです。
もし、親しい間柄の人が改まって②の席に座ったなら、そのような話題になるかもしれないですね。
パターン④ 対角線上

④の位置に座った人は、あなたとは別々の作業をするような人の座り方。
話し合いには適していません。
もし、話をするときにこの席を選ばれてしまったら、あなたとは疎遠な関係であり対立を起こしているかもしれません。
角テーブル?丸テーブル?
角テーブルと丸テーブルでは、座る人の心理によって微妙に異なってきます。
丸テーブルは上座というもの作りずらいので、そのテーブルに座る人たちに公平感が生まれます。
みんなと仲良く議論したい人は丸テーブルを好むようです。
角テーブルは上座というもの作りやすく、リーダーシップを発揮しやすい環境です。
そのため、リーダーシップを発揮したがる人に好まれます。
まとめ
今回は座る位置によって自分に対する相手の心理状態を推測しました。
当たり前ですが、近ければあなたに対して親近感があり遠ければ疎遠な関係でしたね。
この物理的な距離と心理的な距離は比例しています。
逆にこの心理作用を利用することもできます。
例えば、「あの人と親しくなりたいな~」と思ったら物理的な距離を近づけ、心理的な距離を縮めるのです。
物理距離を利用して心理距離を縮めることを「ボッサードの法則」というようです。
しかし、相手にはパーソナルスペーズというものがあり、その範囲内に入ってしますと逆効果になってしまうかもしれません。
なので、パーソナルスペーズにギリギリ入らないだろうという距離を攻めましょう笑
相手のパーソナルスペースなんか知るか!!!!
って思いますよね笑
内向的は人はパーソナルスペースが広く、外交的な人はパーソナルスペーズが狭いです。
つまり、相手の性格によって、近づける物理的な距離は臨機応変に変化させましょうってことですね~。
今回はこちらの本を参考に書かせていただきました!

他人の心理をもっと詳しく知りたい方は読んでみて下さい!
【図解】ニューラルネットワークのソフトマックス関数とは? & Pythonで実装してみた。【連載⑤】

こんにちは、あつかんです。
今回はニューラルネットワークの出力層の設計について説明していこうと思います。
ゼロから作るDeep Learningという本を参考にさせていただいております。

またこの記事は連載形式ですので、下の記事を読んでから読むことおすすめします。
出力層の設計
ニューラルネットワークは、分類問題と回帰問題の両方に利用できます。
分類問題というのは、データのクラス分けです。
例えば、猫の画像を見せたときにそれは猫か?犬か?を分類するような問題です。
回帰問題は、ある入力から何かしらの数値を予測するものです。
たとえば、猫の画像を見せてその画像から猫の身長や体重を予測するような問題です。
分類問題と回帰問題によって出力層の活性化関数の種類が変わってきます。
分類問題ならソフトマックス関数を使い、回帰問題なら前のブログで説明した恒等関数を使用します。
今回は分類問題の焦点をあてていこうと思います。
ソフトマックス関数について
まずは、あらたにソフトマックス関数というものが出てきたので、それについて説明します。
ソフトマックス関数の式は以下のように表わされます。

kはk番目のニューロンの出力であり、nは出力層のニューロンの数です。
分子は入力信号の指数関数、分母はすべての入力信号の指数関数の和です。
図で表すと以下のようになります。

式の通り、一つの出力層に対して、すべての入力が結びついていることが確認できます。
ではソフトマックス関数を使って実際に数値を使って計算してみます。

の時、y1,y2,y3は以下のようになります。



だからなに?って感じですよね笑
次の説明でその疑問を解決します笑
ちなみにPythonで書くとこんな感じになります。
なぜソフトマックス関数なのか?
先ほどの計算結果で示したように、ソフトマックス関数の出力は0~1の実数値に落とし込むことができています。
どんな値を使っても0~1の実数値が出力されるので試してみてください。
この0~1の実数値に収めることができるというのがソフトマックス関数の重要なところです。
なぜなら、出力値を確率として解釈することができるからです。
0.1なら10%、0.25なら25%のように。
確率として解釈できるということは、例えば以下の図のようにニューラルネットワークを利用できますね(かなり強引ですが)。

上図より、ニューラルネットワークに信号(画像のピクセル値)を入力した結果、猫である確率が高いと判断されたました。
つまり、確率として扱うことにより画像に写っているモノは猫であると予測できるわけですね。
猫の画像を入力して、それが猫であるって判断を行うためにはニューラルネットワークを学習させなければなりません。
それについては今後説明します。
まとめ
今回は出力層に使われる活性化関数の一つとしてソフトマックス関数についてまとめました。
出力層にソフトマックス関数を使うと、出力の結果を0~1の範囲に実数値として落とし込めるので、確率的な表現ができることが可能になりました。
確率的な表現ができるということは、予測ができるということなので、なにかを分類するような問題に応用できます。
しかし、なにかを分類するためにはニューラルネットワークの重みなどを適切に設定しなければ正しく分類することができません。
では、ニューラルネットワークの重みはどのようにして設定するのでしょうか?
それはデータから学習させて重みを設定させます。
ニューラルネットワークの特徴はデータを学習し、重みのパラメータを自動で決定できるという点です。
次のブログではどのようにして、データを学習するのかについて述べていこうと思います!
では!
【図解】ニューラルネットワークの実装【連載④】
こんにちは、あつかんです。
今回はニューラルネットワークの実装を行っていきます。
ゼロから作るDeep Learningという本を参考にさせていただいております。
このブログは連載形式ですので、過去のブログ↓を読んでから読み進めることをお勧めします。
3層ニューラルネットワーク
ここでは図に示すような3層のニューラルネットワークを対象に実装していきます。
今回はforward側の流れ、つまり入力層から出力層への信号の伝達の仕方について説明します。

第0層目から第1層目
まずは入力層から第1層への信号の伝達の様子を見てみましょう。

a1(1)を数式で表すと以下のようになります。


a2(1)を数式で表すと以下のようになります。

a3(1)の図は省略しますが、以下の式のようになりますね。

上記の3つの式は以下のように行列の式でまとめられます。
ここで、

です。
このように各ニューロンに対して、信号の総和を計算できました。
ニューロンは信号を受け取ったら、活性化関数h()を通して出力するので、次はそのプロセスを見ていきます。
第1層目のニューロンの中身を詳しく書きました。

上図より、活性化関数を通して出力される信号の式z1(1)は以下のようにあらわされます。

ここで、シグモイド関数を活性化関数として使用すると、以下のようになります。

z2(1)も同様に計算して

z3(1)も同様に計算して

のようになります。
これらを行列の式でまとめると以下のようになりますね。

ここで、

です。
これで第0層目から第1層目までの信号の伝達の様子を確認しました。
第1層目から第2層目
次は第1層目から第2層目までの実装を行います。

上記のような図の流れですので、

つまり、

となります。Z2(2)も同様に

つまり

となります。
これらを一つの行列式にまとめると以下のようになります。

ここで、

です。
これで第1層目から第2層目までは終了。
第2層目から第3層目
次は第2層目から出力層までの実装をしていきます。

ここで出てきたσ()は恒等関数といいます。
これは出力層の活性化関数として利用されます。
恒等関数は入力をそのまま出力関数です。
出力層の活性化関数には、恒等関数、シグモイド関数、ソフトマックス関数のどれかが使われるのですが、今回は恒等関数としました。
出力層の活性化関数に関しては、次の記事で説明してきます。
つまり、出力の結果として


y2もy1と同様にして、


といった式になります。
以上で3層ニューラルネットワークのforward側の説明は終わりです。
まとめ
今回はforwardの流れ、つまり入力から出力方向への伝達処理を理解しました。
実はニューラルネットワークは学習するためにはbackwardの流れ、つまり出力から入力方向への処理も行わなければなりません。
これについて、後ほどの記事に出てくるので少々お待ちくださいw
次回は、出力層の活性化関数について詳しく述べていこうと思います。
続きはこちら
【図解】ニューラルネットワークの活性化関数とは?【連載③】

どうもあつかんです。
今回はニューラルネットワークに使用される活性化関数について説明していこうと思います。
ゼロから作るDeep Learningという本を参考にさせていただいております。
また、このブログは連載形式ですので下の記事を読んでから読むことおすすめします。
活性化関数とは?
活性化関数については
【初心者向け】ニューラルネットワークとは?【連載②】 - IT-LIFEブログ
で簡単な説明がしてありますが、ここでも少し説明しようと思います。
活性化関数とは入力信号の総和をどのように活性化(発火)させるを決定する役割があります。
活性化関数にも複数の種類があり、ステップ関数、シグモイド関数、ReLU関数というものがあります。
過去記事からわかるようにパーセプトロンでは活性化関数としてステップ関数が使われていましたね。
ステップ関数とは下図のように閾値を超えていたら1を出力、閾値を超えていなかったら0を出力するような関数でした。
ここで質問です。
パーセプトロンをニューラルネットワークの世界に拡張させるためにはどうしたらよいでしょうか?
答えは、パーセプトロンで使われている活性化関数を別の関数に置き換えることで、ニューラルネットワークの世界へ進むことができます。
では、ニューラルネットワークで使われている活性化関数を見ていきましょう。
様々な活性化関数
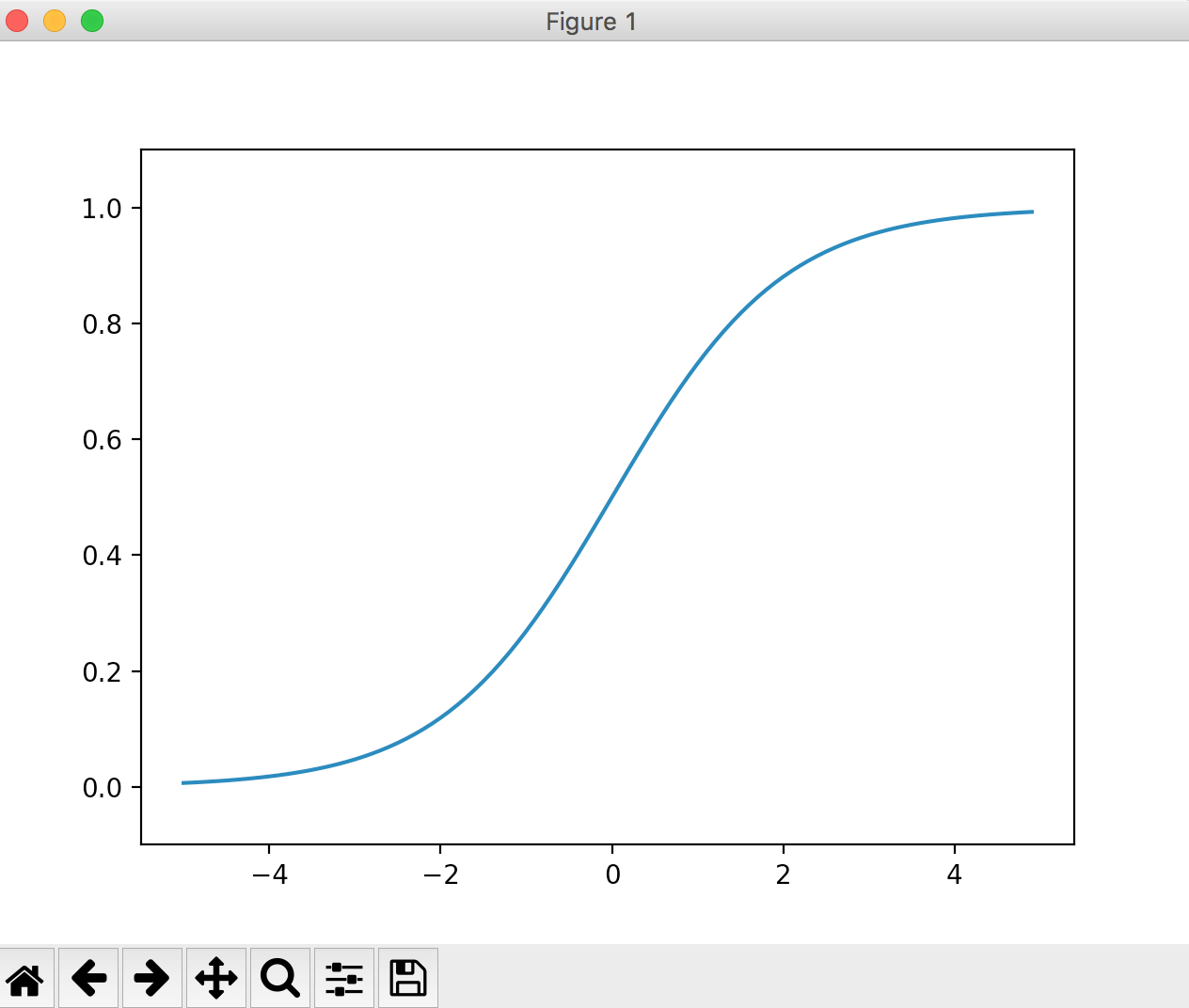
シグモイド関数
シグモイド関数はニューラルネットワークでよく使われる関数の一つです。
式は以下のようにあらわされます。

exp(-x)はeの-x乗という意味です。eはネイピア数で2.7182.......の実数です。
グラフは下図のような形になります。
ニューラルネットワークとパーセプトロンの主な違いは、この活性化関数だけです。
パーセプトロンはステップ関数、ニューラルネットワークはシグモイド関数など。
これだけなのです。
それではステップ関数とシグモイド関数を比較するためにグラフを重ねてみます。
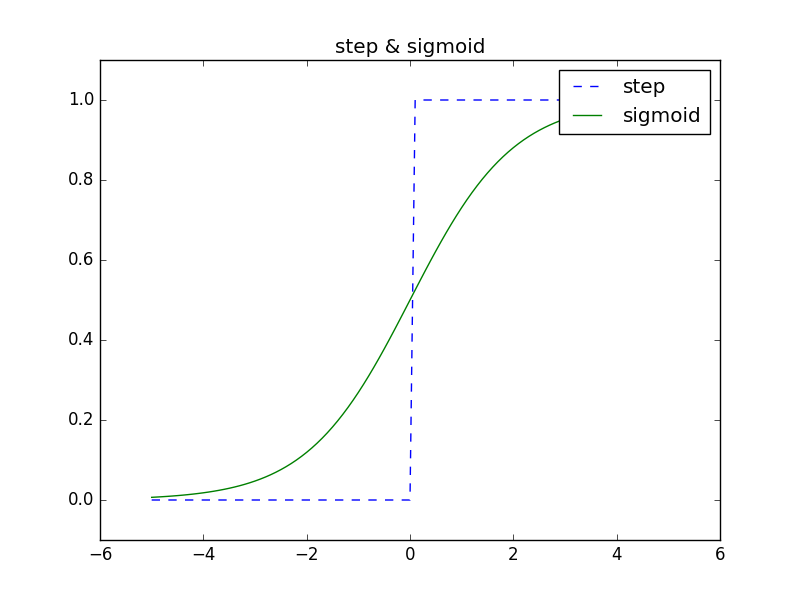
この図をみて気づく点は、グラフの”滑らかさ”の違いだと思います。
シグモイド関数は入力に対して連続的(滑らかに)に変化していますが、ステップ関数は0を境にして急激に値が変化しています。
この違い、つまりシグモイド関数の滑らかさがニューラルネットワークの学習において重要な意味をもっています。
その理由は今後の記事で紹介していきます。
また、ステップ関数は1か0の値のみしか出力しませんが、シグモイド関数は0から1の間の実数(0.37469や0.98893など)を返します。
つまり、デジタル的な変化でなく、アナログ的な変化を含ませたわけです。
人間の脳はアナログの情報でやり取りしていますので、それに近づいたわけですね。
ステップ関数とシグモイド関数の共通点として、両者とも入力が小さいときほど小さい値を出力し、入力が大きい値ほど大きい値を出力しています。
つまり、重要な信号であれば大きな値を出力し、重要でない信号であれば小さな値を出力します。
また、出力の値は0から1の間のみだということもわかります。
ReLU関数
これまでに、活性化関数としてステップ関数とシグモイド関数を紹介しました。
シグモイド関数はニューラルネットワークの歴史において古くから使用されています。
しかし、近年ではReLU (Rectified Linear Unit) 関数という活性化関数が主流となっているようです。
この関数は0を超えていれば入力の値をそのまま出力し、0を超えていない場合は0を出力するといった単純な関数です。
図で表すとこんな感じ。
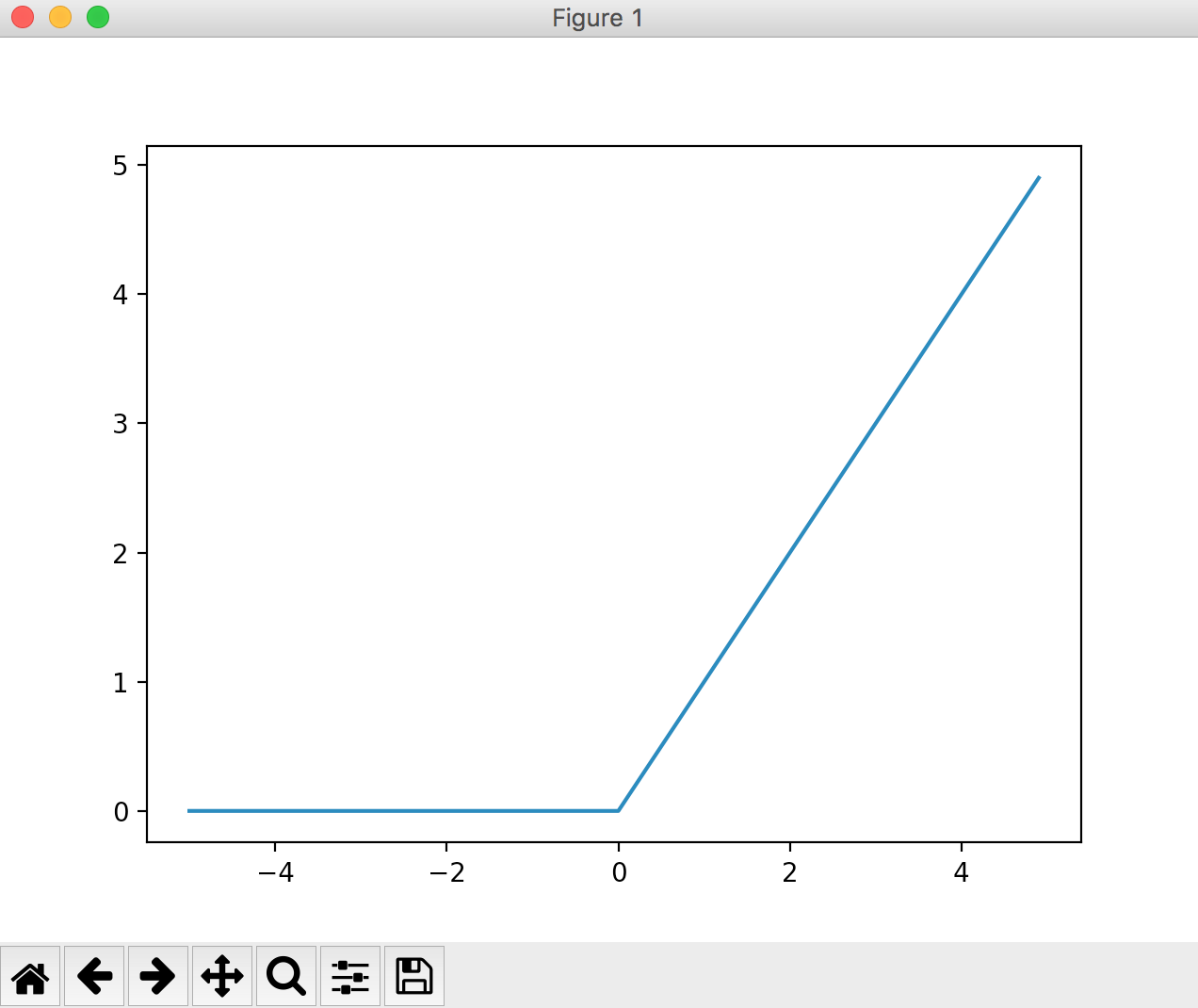
式で表すとこんな感じ。

とても簡単な式ですね。
閾値以下の入力は0(重要でない)、閾値以上の入力は入力の値をそのまま出力、つまり重要度に比例した値を出力するといった機構ですね。
以上で活性化関数の説明は終わりです。
まとめ
今回は活性化関数について紹介していきました。
パーセプトロンの活性化関数はステップ関数であり、その活性化関数をステップ関数以外の関数に置き換えることにより、パーセプトロンをニューラルネットワークの世界に持っていけるということが分かりました。
ステップ関数以外の関数とは、シグモイド関数、ReLU関数などでした。
ではなぜ、シグモイド関数や、ReLU関数がニューラルネットワークに使用されるのか?
それは二つの関数にはステップ関数にはない”滑らかさ”があるからでした。
その”滑らかさ”が、ニューラルネットワークの得とする”学習”にとって非常に大切な意味を持ちます。
なぜなのか?
それについては今後のブログで書いていきますのでご安心を♪
ではでは。
続きの連載④はこちらです。
【ブログ一ヶ月目】2017年11月の収益&アクセス数報告

こんにちは、あつかんです。
今日で12月ということで、先月の収益&アクセス数を報告していこうと思います!
はい!皆様が大好きなお金に関する話ですw
実は、ブログ開設は今年の3月にしていたのですが、本格的に始めたのは今年の11月ですのでブログを始めてから一ヶ月目という目線でみていってください(; ・`д・´)
先月の目標として
・アクセス数:1000
・収益:まずはアドセンスの審査通過(通過したら100円以上)
を目標としておりました。
まずはアクセス数について述べていきます!
アクセス数
結論から申し上げますと、先月のアクセス数は2615でした!

第一の目標は達成( ;∀;)うれしい~~
ちなみに一番アクセス数を稼いだブログはこれでした。
近年トレンドの人工知能系のブログですね。
ホットなニュースを記事にしたら、ぷちバズが起こりました。
時事ネタ最高!
また、アクセス数の時系列データはこちら↓のような結果に。

ぷちバズを起こした記事は28日の21時頃に投稿していたので、やはり29日が盛り上がってますね。
あと、一回バズった記事は日がたってもアクセス数を稼いでくれます。
つまりバズ記事は残しておけば財産となるわけですね笑
アクセス元はというと、ほとんどがGoogle検索でした。

Google検索の結果、私のブログが検索の上位に反映されたってことですよね!
これはうれしいです!
てなわけで先月のアクセス数でした!
収益
先月の時点ではアドセンスが通ってなかったので、まずはアドセンス通過を目標に掲げてました。
結果は、、、、、
通過!!
いや~通過した時はうれしかったです。
それについて詳しくはこのブログに書いてあります。
11月21日に通過の結果がきたので、収益は21日~30日の10日間の収益となります。
ちなみに収益はアドセンスのみです。
収益の結果は、、、
牛丼大盛一杯くらい
です。
具体的な数値はGoogleさんに怒られそうなので控えました笑
一ヶ月目にしてはいいほうだと思っています。
てなわけで、収益に関しても目標は達成!
今月の目標
先月はブログの記事数を目標に設定していなかったので、今月はそれも組み込もうと思います。
・ブログ数:20記事
・アクセス数:3000
・収益:800円以上
が目標です!
がんばらねば~~~。
終わりに
今日もたくさんの読者様がこのブログに来てくれていることに感謝しています。
そのおかげで私はブログを続けられています。
ありがとうございます。
今後とも頑張っていきますので、よろしくお願いします。
また、最後まで読んでくださいまして、ありがとうございます。
もしよろしければ、読者登録していただけると大変励みになります。
よろしくお願いします。
では、あつかんでした!
【図解】ニューラルネットワークとは?【連載②】

どうも、あつかんです。
今回はニューラルネットワークについて述べていこうと思います。
ゼロから作るDeep Learningという本を参考にさせていただいております。
ニューラルネットワークについて述べるといっても、この記事ではすべては述べません。
全て述べると、本一冊書けちゃいますからねw
なので理解するにあたって必要最低限な知識を一歩一歩、順に複数のブログで連載形式で説明していきます。
遠回りのように見えますが、これが一番の近道だと思います。
まず、ニューラルネットワークを学ぶためにはパーセプトロンについての知識が必要です。
パーセプトロンについては下の記事にまとめてあります。
このブログは連載形式ですので、下の記事を読んでからこのブログを読むことをお勧めします。
ニューラルネットワークは簡単に言うとパーセプトロンの弱点を補ったものです。
では、パーセプトロンの弱点とはなにか。
それは、重みを設定する作業が人の手によって行われているという点です。
これは大変な作業であり、汎用性が生まれません。
このような弱点はニューラルネットワークによって解決できます。
具体的に言うと、適切な重みパラメータはデータから自動で学習できるという点です。
これがニューラルネットワークの重要な性質の一つになります。
では、その学習する方法を述べる前にまずはニューラルネットワークの概要について説明していこうとおもいます。
ニューラルネットワークの導入
ニューラルネットワークの例を図で表すと下の図のようになります。

入力層から始まって中間層(隠れ層)を経て出力層に伝わります。
ここで少しパーセプトロンの説明をします。
パーセプトロンは前のブログでも述べた通り、例として以下の図で表現できます。

パーセプトロンを数式で表すと以下のように表わせました。
b+x1w1+x2w2<=0の時
y=0
b+x1w1+x2w2>0の時
y=1
ここでbはバイアスパラメータといいます。
この値は任意で設定でき、ニューロンの発火のしやすさをコントロールできます。
w1、w2は各信号の重みを表わすパラメータであり、これは各信号の重要度をコントールできます。
しかし図にはbが定義されていません。
bを図に表わすと以下のような図になります。

ここで、パーセプトロンの式をシンプルな式に書き換えたいと思います。
y = h(b + x1w1 + w2x2)
h(a) = 0 (a <= 0)
h(a) = 1 (a > 0)
上記の式は
a= b + x1w1 + w2x2が0以下の時は
h(b + x1w1 + w2x2) = 0
つまりy = 0
a = b + x1w1 + w2x2が0を超過した時は
h(b + x1w1 + w2x2) = 1
つまりy = 1
ということを表わしています。
活性化関数h(a)について
いきなりh(a)が出てきて困惑したと思いますが、これは活性化関数と呼ばれるものです。
活性化関数は式の通り、入力の総和をどのように発火(活性化)させるかを決定します。
もう一度活性化関数の式を書きます。
a = b + x1w1 + x2w2
y = h(a)
aでは総和が計算され、aをh()の中にいれてyで出力するという機構になっています。
活性化関数を図の中に組み込むと以下のような感じ。

この図より、入力の重み付き信号の総和がaに入り、そしてaが活性化関数h()を通ってyに変換されていることが分かります。
活性化関数はここでは一つを紹介しましたが、実は複数存在します。
次のブログではどんな活性化関数があるのか?なぜ複数あるのか?について詳しく述べていこうと思います。
この段階ではニューラルネットワークについてまだ全然理解できていないと思いますが、まだ大丈夫です。
これから徐々に書いていきますので!
では!
次の連載はこちらです。